

Driving a supply chain transformation? Want to be data-driven?
Prepare for the journey by redefining your relationship with data. And encourage your organization to do the same.
Data has a cycle as described by this quote from Techtarget.com. Most organizations only focus on usage. To be demand-driven, own the cycle.
Data management is the process of ingesting, storing, organizing, and maintaining the data created and collected by an organization.
Techtarget.com
Definitions
Let’s start with some definitions.
In this blog, I will challenge traditional paradigms. During the year, I challenge you to move from a schema-on-write paradigm to invest in schema-on-read solutions. The goal is to not stub your toe getting the data you need to give you more time to listen and learn from the data to drive process enablement. The reason? Schemas change over time, and semantics are important.
Traditional supply chain applications are schema-on-write architectures. Definition? Traditional architectures use relational database. The models define the schema, table creation, and data ingestion. The catch-22? Data cannot be uploaded to the tables without a schema and tables need to be created and configured. The problem? Schema-on-write architectures limit the supply chain team’s ability to easily source data. Schemas change and evolve. In the process, semantics are lost. ETL processes require a high dependence on IT processes which can be long and laborious. For most, this is a bottleneck.
The schema-on-read concept is the opposite of the schema-on-write construct. The database schema is created when the data is read. The data structures are not applied or initiated before the data is ingested into the database; instead, they are created during the ETL process. This enables unstructured data to be stored and used. The primary reason for developing the schema-on-read architectures is the exploding growth of unstructured data volumes, the inflexibility of schema-on-write architectures, and the high IT overhead involved during the schema-on-write process.
Last week, I attended Kinexions. And, while the program mistakenly hung the term “AI” all over the agenda leaving me sitting in my chair searching for use cases that defined value, the significant piece of the announcement of Maestro (replacing Rapid Response as a product naming convention), is the creation of Data Fabric to create an in-memory schema on-read architecture. This enables the ingestion of unstructured data and reduces ingestion issues in the face of changing semantics. I am proud of Kinaxis for taking this step.
I expect other tech companies in the space to follow. The evolution of the graph, Vector DB, machine learning, and the use of unstructured data in supply chain planning technologies offers promise.
Why It Matters
As shown in Figure 1, most companies rate themselves higher on their ability to use data than getting access. Bottomline? Today, business users cannot access data at the speed of business. The cadence of getting and using data is out of sync with decision cycles. The answer is not more Enterprise Resource Planning (ERP).
Figure 1. Effectiveness of the Average Company to Access and Use Data in the Enterprise
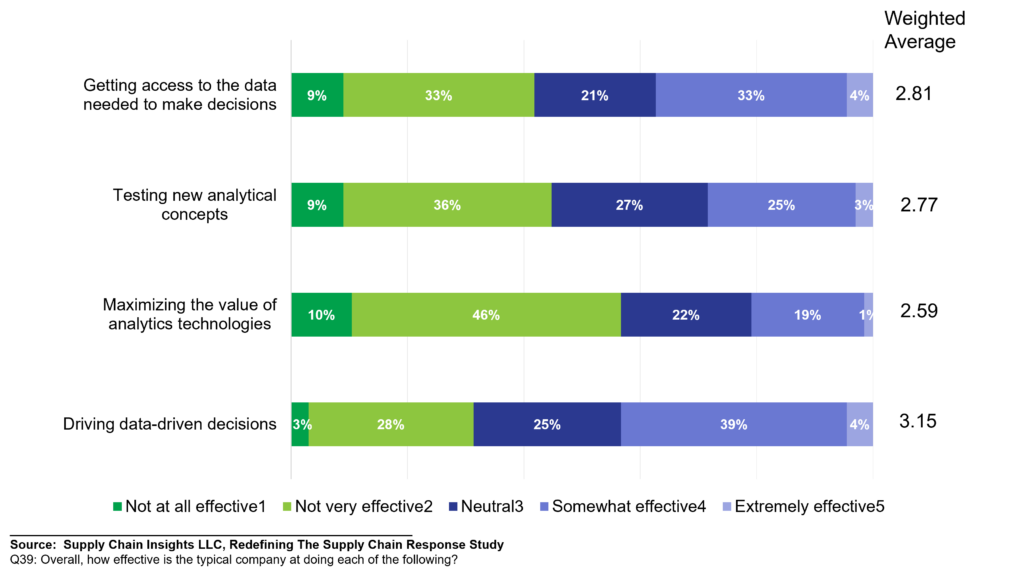
While over 90% of companies have supply chain planning, for 94% of companies their primary planning technology is a spreadsheet. The reason is usability and control. The testing of new analytical concepts and the justification of new approaches is a challenge.
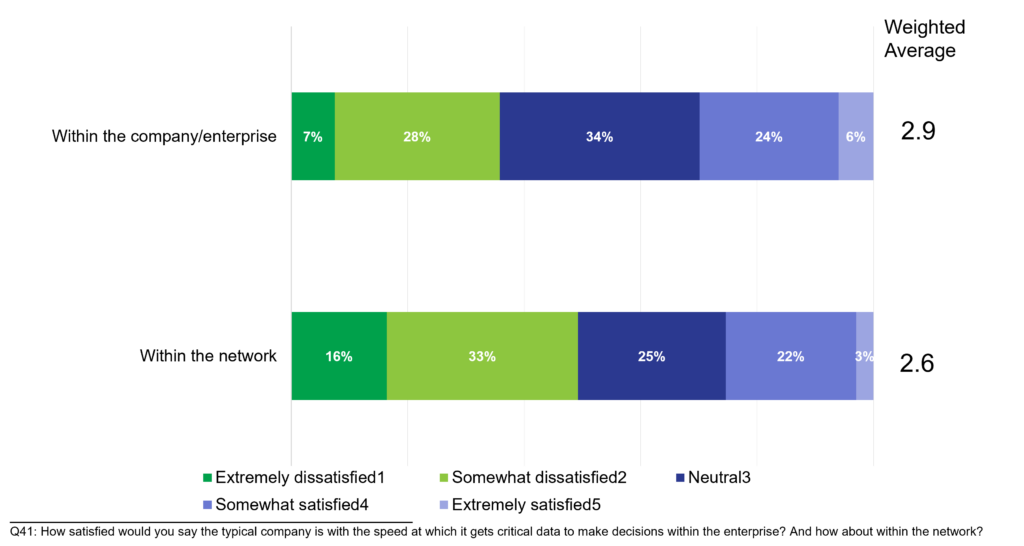
As shown in Figure 2, the issues of data access within the network–where 70% of the impact of carbon and water on the planet occur–is worse than data access within the enterprise. (Significantly worse at an 80% confidence level.)
Current network technologies have improved the user interface, but not the movement and sourcing of data. Vector Database (Vector DB) approaches offer promise to enable better access to network data. Vectors are lists of numbers. Embeddings are vectors that have rich, machine-understandable information baked into them. In Vector Database structures, images, text and audio are converted into embeddings.
Figure 2. Ease of Getting to Data in Enterprise and Network Architectures
Redefining Your Relationship with Data
So, as you think about schema-on-read architectures and the evolution of Vector DB for network data, challenge your paradigms: become more data-driven. Think past current supply chain models and engines to redefine your relationship with data. Side-step the hype of AI everywhere, but nowhere. Adopt these principles:
- Data Does Not Have to Be Pristine, Clean and Odor Free. Free Data from Data Jails. In the schema- on- write world, data cleansing was a pre-requisite. Master data management (MDM) was a never-ending, and thankless, job. Free yourself from traditional paradigms and use machine learning to clean data and understand data patterns.
- Listen. Learn. Evolve. Staff Data Scientists in Line of Business Teams. Build self-service architectures and lower your dependence on IT. Use machine learning concepts to understand patterns and answer the questions that you do not know to ask.
- Focus on Flow and Visualization. In the use of traditional approaches, data is often viewed in time-phased graphs and charts. I encourage you to use Graph Databases to depict flow and the shifts in the market. Use new forms of visualization to help teams understand bi-directional and multi-tier flow.
- Align the Right Tool for the Right Job. While the market is exploding with generative AI hype, relax and take a breath. Large language models are not well-suited for math modeling. Develop generative AI models in areas where learning on unstructured data is important. For example, in Consumer Products, brokers canvas stores taking pictures and recording notes on shelf-sets, price compliance, and planogram usage. The data is never used. This could be a great Large Language Model (LLM) to understand market execution. Similarly, if you want to understand customer sentiment, mining email and call center data in large language models would allow the organization to listen to the voice of the customer. This is a far better strategy than an annual survey or a net promoter score.
- Time Versus Insights. Get Clear on the Role of Time. There is always tension between the time to run an engine/model and the need to get an answer fast. Understand which processes need to be accomplished quickly and which take time to assess. Define the speed of business and adjust your business cadence. Don’t get caught up in the conversations on real-time. Instead, adjust your thinking to define what is needed.
- Get Familiar with Your Data. In most companies, teams are not aware of the data that they have. Most supply chain teams are only familiar with structured transactional and time-phased data used in everyday processes. They are not aware of the data used by the sales account teams, marketing, or R&D. Explore a bit. Brainstorm with cross-functional teams to understand the data in the organization and potential use cases.
- Analytics Centers Outperform Supply Chain Centers of Excellence in Satisfaction. Invest in building a Center of Analytics Excellence. Centers of Analytics Excellence outperform centers of Supply Chain Excellence. The world of analytics is changing fast requiring the learning and testing of new architectures. Challenge your team to listen and learn while testing new forms of analytics.
- Be Open to Outcome. Focus on Orchestration and Explainability. One of the key principles of data-driven approaches is listening to the data and being open to the outcome. In many companies where business users think that they know the answer or are trying to push a fixed agenda, this is an issue. Drive process orchestration. Don’t just match demand and supply at a volume level. Instead, design and pull orchestration levers bi-directionally and cross-functionally with a focus on volume/profitability trade-offs.
Figure 2. Bi-Directional Orchestration Levers

Wrap-Up
Many companies say they want to be data-driven, but they are not actively managing the cycle of data ingestion, processing, and storage. New techniques make this easier, but only if they are actively deployed.
I look forward to getting your thoughts.






