
 The elephants are coming! They will soon change your supply chain. In time, you will come to love them. I think that they will be a game changer. What do I mean? Let’s start with a story.
The elephants are coming! They will soon change your supply chain. In time, you will come to love them. I think that they will be a game changer. What do I mean? Let’s start with a story.
Designed in the 1960s when a Megabyte (MB) of disk storage cost the same as a Terabyte (TB) does today, relational databases form the basis of today’s supply chain systems and IT architectures. The limitations of these early computing systems shaped the first and second generation of supply chain solutions. Today, we are living with the limitations.
We are now moving to the third generation of supply chain solutions which are no longer bounded by these limitations. I term this generation applications the third act. (I have written several blogs on what I think the third act will look like.)
A Look at History
Despite the fact that the cost of memory decreased a million-fold in 55 years, the majority of supply chain solutions use relational databases from vendors like Oracle, SAP or Teradata. The data is logically expressed in rows and columns. To connect data from system to system, the data is moved and integrated. As a result, everywhere you go, users and teams complain about the inadequacies of transaction master data and the problems of data integration.
In contrast, when you go to your favorite search engine–Google, Bing, Yahoo–software quickly indexes web pages for your specific search. I have never heard Google struggle with a master data issue. Why? They index. Index is a data structure that maps each term to its location in text to enable all of the web pages using that term to be quickly displayed when a term is entered by the user. It makes searching large data sets fast. Doug Cutting and Mike Carafella, in an effort to improve searching, created a distributed storage system termed Hadoop. (Doug named the software after his son’s favorite pet elephant shown here.) As a result, the symbol for Apache Hadoop is an elephant. 
Hadoop is an open-source software framework written in Java for distributed storage and processing of large data sets on computer clusters. Hadoop splits files into large blocks and distributes the data over the nodes in the cluster. A key principle of the design is that users should not have to move data in order to process data for answers. Instead, the program processes the data where it resides. This is a key differentiator and vastly different to the principles we know today of relational software in rows and tables, and traditional data warehouse approaches using ETL where processing data requires movement. Ask yourself the question, “What if we did not have to move and integrate data to get valuable answers?”
The first step is to get educated and learn the terms to have a new discussion. The base Apache Hadoop framework building blocks:
- Hadoop Common – contains libraries and utilities needed by other Hadoop modules;
- Hadoop Distributed File System (HDFS) – a distributed file system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster;
- Hadoop YARN – a resource-management platform responsible for managing computing resources in clusters and using them for scheduling;
- Hadoop MapReduce – a programming model for large-scale data processing.
- Apache Spark – Brings capabilities for streaming, machine learning and graph processing capabilities.
- Ecosystem Software – Apache Pig, Hive, HBase, Phoenix, Zookeeper, Impala, Flume, Oozie and Storm.
Why Should You Care? The first answer is that it’s cheaper. The Hadoop approaches to data management are about 1/5th the cost of relational database approaches. The second is that it enables new capabilities. Hadoop enables users to bring structured and unstructured data together in a natural state (think file folders) and then query or index based on need. There is no longer a need for ETL extraction and direct data integration. The data is not moved. (In computing, Extract, Transform and Load (ETL) refers to a process in database architectures that extracts data from homogeneous or heterogeneous data sources, and transforms the data for storing it in proper format or structure for loading. Vendors include IBM, Informatica, Oracle, and SAS. )
While the rest of the world was deep in a recession in 2008, and manufacturers were struggling with payroll decisions and layoffs, Hadoop innovation was in full swing. Facebook contributed Hive, the first incarnation of SQL on top of MapReduce, and Yahoo! introduced a higher-level programming lanaguage on top of MapReduce termed Pig. In 2010 a vendor architecture evolved with Cloudera providing packaged Hadoop solutions, and Hortonworks providing Hadoop IT services.
While Hadoop was first developed to handle large data sets (think petabytes of data) and circumvent disk failure in parallel processing for ecommerce and online search engines, what I find interesting is the application of the technology to bring disparate data sources together in unique ways at a lower cost. So while the rest of the world is debating SAP HANA (a columnar database architecture designed for fast transactional data loading and processing), and cloud-based in-memory analytics (like Qlik which I love), I want to throw in a wrinkle. Isn’t there also a place for Hadoop in this discussion on future supply chain architectures?
In my simple world I see SAP HANA as the answer for faster and more robust Enterprise Resource Planning (ERP). HANA plays an important role in improving the scale of transactional data. ERP is important to building transactional systems of reference, but I do not see it as the foundation for future analytics. Why? Let me explain. Not all supply chain data is transactional in nature. Planning data is time-phased data, and sensor data (like the Internet of Things and RFID) is streaming data. I do not see HANA as the ideal structure for streaming and time-phased data. (I base this belief on interviews with companies testing the architecture for planning and IOT approaches.)
However, let’s take this discussion a step further. Our paradigm is currently structured data (fitting into rows and columns); but, what about unstructured data? I think that unstructured data is key to the future of supply chain management. Think of the possibilities for the use of social data, pictures, images, email, warranty data, weather data, social data, GPS map data. For me, the possibilities are endless; but the unstructured data cannot not fit into today’s supply chain management systems. What if you could combine unstructured data with structured data in its natural state without moving data for forced integration. This is where I see Hadoop playing a role.
Let me explain using some supply chain specific examples; but, before I do, let me give you a disclaimer. I am not a technical gal. You will never find me writing code on a weekend. Instead, I am a business gal studying the use of new technologies in supply chain management. While I have written software requirements, I have learned enough to know this is not me: I have great admiration for software developers. I write for the business buyer, not CIOs or Directors of IT. As a result, while this blog post is on a technical subject, I will try to stay out of the technical jargon; and as a result, some software experts may find this analysis incomplete. My goal is to stir a debate.
Application to Supply Chain Processes
Most consultants will say that the answer lies in Big Data. To me this is rubbish. Why? Big Data is an overused term that lacks meaning. The supply chain problem is not usually large (less than a petabyte of data), but for me the promise lies in rethinking the use of a variety of data types and the use of higher velocity data. (For more on this topic, visit the blog Rethinking the Bits.) To take an academic argument into practical examples, let me share five use cases where I think Hadoop might make sense.
Market-Driven Forecasting: Historically, the use of linear optimization and genetic algorithms to sense future trends from order and shipment patterns and predict the future defined forecasting. With the increase in demand latency (the time for market demand to translate to an order) and the impact of the Bullwhip Effect, the time lag for traditional forecasting to sense market patterns from orders is weeks for retailers, weeks and months for first-tier manufacturers, and many months for second- and third-tier manufacturers (like chemical, semiconductor, mining, etc.). This has grown longer with the proliferation of items, personalization of product offerings, and the increased complexity of new product launch within the supply chain. There are two major shifts: the Bullwhip Effect depicted in Figure 1 is greater, and the long tail shown in Figure 2 is growing.
Figure 1. The Bullwhip Effect of Demand Translation Based On Order Patterns and Shipments

Figure 2. Impact of the Long Tail of the Supply Chain on Demand Sensing.
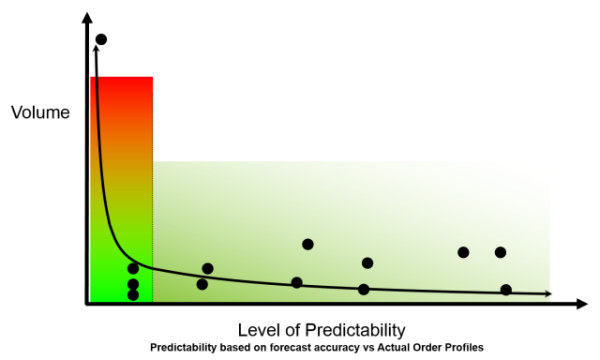
In essence, what we built through these first and second generation applications, which we term forecasting, is order prediction not market forecasting. Why is this a problem? The tactical processes of forecasting in this conventional analysis cannot sense markets fast enough to slow or speed up processes.
Let me give you an example. In the recession of 2008 it took the average consumer products company three to five months to sense the recession and redefine product plans. In contrast, it took the average chemical company or automotive supplier five to eight months. As a result companies closed manufacturing facilities. Today we live in volatile times. Inventories are high and we have excessive ocean capacity. Is this a sign of a looming recession or a transportation opportunity? Truckload capacity is starting to surge for the holidays, but companies worry that market growth is stalled. The growth expectations of the BRIC countries is worrisome. What is the market potential of these emerging economies?
Today, companies do not know. Traditional forecasting systems are not adequate. The Bullwhip Effect distorts the signal, and the growth of the long tail of the supply chain makes this worse today than a decade ago. Based on what happened in the last recession, I only know of four companies that built a market-driven forecasting system. A market-driven forecasting system uses market forces and trends to forecast future aggregate demand. It is an indicator of market health. For example, for an automotive supplier it could be the sales of automobiles, and for a crop protection company selling herbicides it might be the number of acres planted and the market price for crops (a strong determination on whether to turn crops under versus treating crops in the field). It could be weather or customer sentiment. What if you could take all of the market drivers affecting your market and allow automatic updates. When you want to do an analysis you would use SAS, or R, or cognitive reasoning, using Enterra with a Hadoop architecture to access the market indicators and run models based on the market. You could then use this as a market-driven forecast.
(I will explain the next examples with less detail, but the principles of data extraction and the use of Hadoop remain the same.)
Demand Sensing and Market Analysis. I recently visited a large beverage company that has three point-of-sale systems, four customer insights databases, and numerous retailer information sources. They used a visualization tool, Trifecta, on top of a Hadoop platform from Cloudera to analyze market baskets, trip types, promotion effectiveness and market launch effectiveness.
Redefinition of Planning Master Data. Today’s average company has six Enterprise Resource Planning (ERP) systems, and 20 different engines running supply chain planning (two to three each in demand planning, supply planning, production planning, and transportation planning). Engine effectiveness is only as good as the fit of the data model and the accuracy of the inputs. Most systems, correct when implemented, have not been updated with correct planning master data.
What is planning master data? Planning master data are the assumptions on lead times by lane, change-overs, run times, cycle constraints, planned maintenance, and production floor restrictions. Keeping this data updated is difficult. So what if you could have the systems files from ERP and MES in a natural state in Hadoop and use Indexing to find the best assumption for planning master data and keep it current? I see this as a quarterly task to ensure that the engines are all running using the same and current planning master data. Today, getting to this data is not easy.
Streaming Data. Digital manufacturing, cold chain technologies, robotics, and transportation telematics have one thing in common. What? Successful implementation is dependent on the successful use of streaming data. Streaming data emits a signal at a high frequency, and the signal requires conversion into a usable data feed. The use of Apache Spark on Hadoop is the preference for RFID vendors like Savi Technology and Translink.
Cognitive Learning. We are starting to see the evolution of cognitive computing in supply chain technologies. Cognitive computing enables continuous learning and answers the questions that you do not know to ask. The technologies can work on top of relational or non-relational technologies, but what if you could continually test and learn on your planning data while leaving your system data in a native form?
The options are endless. These use cases provide a framework to spark a new conversation.
Conclusion:
So, why do I love the thought of Hadoop? Three reasons:
- I think that it opens up new possibilities for the supply chain leader to solve new problems.
- I love the innovation and the fact that it is open source.
- It allows the supply chain leader to reach their goals cheaper and faster without long and involved IT projects.
What do you think of the use of Hadoop in supply chain management? Any thoughts to share? I would love to hear from you either here or in the Beet Fusion Community.
![]() What is Beet Fusion? Beet Fusion is a community designed for supply chain leaders around the world to have healthy conversations on the evolution of supply chain practices. Our goal is to make it the Facebook, LinkedIn, Yelp, and Monster for the supply chain community. We launched it in a Beta format two weeks ago and we currently have over 600 community members. Feel free to post jobs in the community, engage in a discussion, or add content. This week we are starting ratings and reviews of technology providers. (We think this assessment should be by supply chain leaders as opposed to analysts in conference rooms on white boards.)
What is Beet Fusion? Beet Fusion is a community designed for supply chain leaders around the world to have healthy conversations on the evolution of supply chain practices. Our goal is to make it the Facebook, LinkedIn, Yelp, and Monster for the supply chain community. We launched it in a Beta format two weeks ago and we currently have over 600 community members. Feel free to post jobs in the community, engage in a discussion, or add content. This week we are starting ratings and reviews of technology providers. (We think this assessment should be by supply chain leaders as opposed to analysts in conference rooms on white boards.)
In addition, we are putting the finishing touches on our agenda for the Supply Chain Insights Global Summit in September. We have confirmed four speakers. The dates are September 7-9th at the Phoenician in Scottsdale, AZ. We hope to see you there!
About the Author:
 Lora Cecere is the Founder of Supply Chain Insights. She is trying to redefine the industry analyst model to make it friendlier and more useful for supply chain leaders. Lora wrote the books Supply Chain Metrics That Matter and Bricks Matter, and is currently working on her third book, Leadership Matters. As a frequent contributor of supply chain content to the industry, Lora writes by-line monthly columns for SCM Quarterly, Consumer Goods Technology, Supply Chain Movement and Supply Chain Brain. She also actively blogs on her Supply Chain Insights website, for Linkedin, and for Forbes. When not writing or running her company, Lora is training for a triathlon, taking classes for her DBA degree in research at Temple or knitting and quilting for her new granddaughter. In between writing and training, Lora is actively doing tendu (s) and Dégagé (s) to dome her feet for pointe work at the ballet barre. She thinks that we are never too old to learn or to push an organization harder to improve performance.
Lora Cecere is the Founder of Supply Chain Insights. She is trying to redefine the industry analyst model to make it friendlier and more useful for supply chain leaders. Lora wrote the books Supply Chain Metrics That Matter and Bricks Matter, and is currently working on her third book, Leadership Matters. As a frequent contributor of supply chain content to the industry, Lora writes by-line monthly columns for SCM Quarterly, Consumer Goods Technology, Supply Chain Movement and Supply Chain Brain. She also actively blogs on her Supply Chain Insights website, for Linkedin, and for Forbes. When not writing or running her company, Lora is training for a triathlon, taking classes for her DBA degree in research at Temple or knitting and quilting for her new granddaughter. In between writing and training, Lora is actively doing tendu (s) and Dégagé (s) to dome her feet for pointe work at the ballet barre. She thinks that we are never too old to learn or to push an organization harder to improve performance.
Sources used: The History of Hadoop, https://medium.com/@markobonaci/the-history-of-hadoop-68984a11704#.9uvrdzt2x, November 28, 2015






